论文:Parrot: A Progressive Analysis System on Large Text Collections [pdf]
作者:张亚中
导师:荆一楠
报导链接:DSE精选文章 | Parrot
简介:
随着互联网和社交媒体的发展,文本数据的规模迅速地增长,对文本数据即时性分析的需求变得越来越强烈。然而,计算能力却无法保持同样速度的增长,这导致在处理大规模文本数据时,将会产生较大的延迟。在交互式分析中,这种延迟会对用户的判断和操作带来负面影响。此外,在交互式分析过程中,用户对结果精准度的期望或对响应延迟的容忍度,往往会随着各种因素而不断地发生不可预期的变化。因此,这些需求驱使着计算模型从阻塞式转变为渐进式,即在较短延迟内计算出一个近似结果,并随着查询等待时间的增加,不断精化近似结果,逐渐逼近精确结果。然而,对于文本数据,现有的研究工作中还没有一种通用的计算引擎能为用户在精准度和延迟之间提供一个平滑的转换。
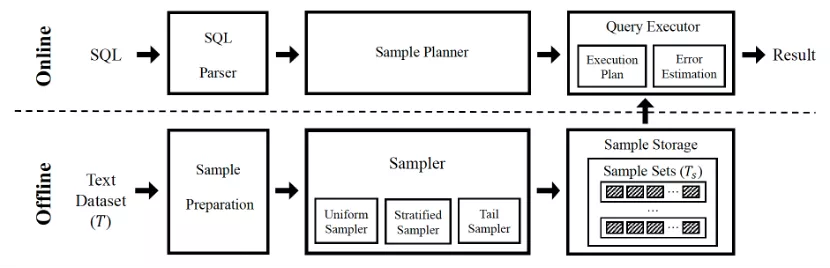
针对上述问题与挑战,本文提出了一个基于采样的渐进式词频计算模型。渐进式词频计算模型有三个主要特征:(1)该模型基于增量式计算引擎,并专注于文本的词频、TF-IDF 等相关分析方法;(2)对于每个分析任务,该模型首先会在较短时间内,在较小规模的样本上计算出一个近似结果;(3)该模型会在用户等待时间期间,以增量的方式不断扩大样本规模,来精化先前的近似结果,以逐步给用户更精确的反馈。总的来说,本文的模型可以为用户在进行文本词频等相关分析时,提供在精准度和延迟之间平滑的过渡。此外,作为模型的一部分,本文提出了一种新的基于重抽样Bootstrap 的渐进式误差估算的方法,以快速的计算每个近似结果的置信区间。
本文基于Apache Spark,设计并实现了Parrot系统(下图),实现了本文提出的模型和方法,并使用真实数据测试了其性能。实验表明,以获得1%误差范围内的结果为目标,相比较于阻塞式的计算方式,本文的方法可以带来2.4 -19.7倍的速度提升,而且,本文提出的渐进式误差估算方法可以快速的为近似结果计算出置信区间。