论文:Learning-based Sample Tuning for Approximate Query Processing in Interactive Data Exploration
期刊:TKDE 2024
作者:Hanbing Zhang, Yinan Jing, Zhenying He, Kai Zhang, and X. Sean Wang
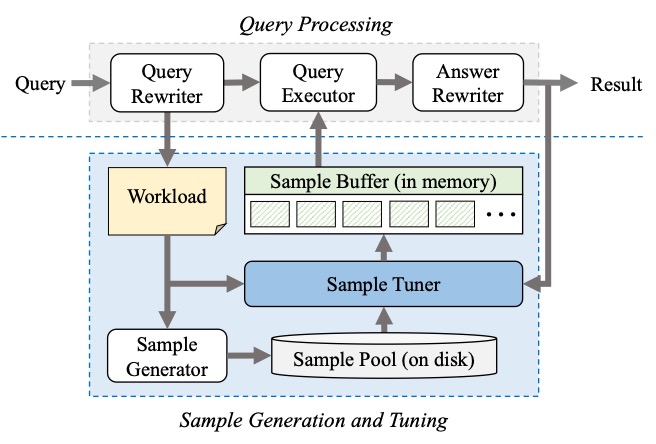
简介:For interactive data exploration, approximate query processing (AQP) is a useful approach that usually uses samples to provide a timely response for queries by trading query accuracy. Existing AQP systems often materialize samples in the memory for reuse to speed up query processing. How to tune the samples according to the workload is one of the key problems in AQP. However, since the data exploration workload is so complex that it cannot be accurately predicted, existing sample tuning approaches cannot adapt to the changing workload very well. To address this problem, this paper proposes a deep reinforcement learning-based sample tuner, RL-STuner. When tuning samples, RL-STuner considers the workload changes from a global perspective and uses a Deep Q-learning Network (DQN) model to select an optimal sample set that has the maximum utility for the current workload. In addition, this paper proposes a set of optimization mechanisms to reduce the sample tuning cost. Experimental results on both real-world and synthetic datasets show that RL-STuner outperforms the existing sample tuning approaches and achieves 1.6×-5.2× improvements on query accuracy with a low tuning cost.
This paper proposes a learning-based sample tuner, called RL-STuner, which tunes samples from a global perspective by using a deep reinforcement learning model. When tuning samples, RL-STuner learns from all appeared queries and leverages this global knowledge to guide sample tuning. To avoid the heavy overhead for computing the optimal sample set from a large number of possible combinations of samples, RL-STuner uses a Deep Q-learning Network (DQN) model to get an approximate optimal solution, which stores the feedback of tuning samples in different episodes and uses them to guide the sample selection in one sample tuning. Furthermore, we propose three optimization mechanisms to reduce the sample tuning cost in RL-STuner. First, we propose a lazy sample tuning strategy to reduce the sample selection and tuning operations during tuning. Second, we use a parameter transfer approach to initialize the DQN model in the sample tuning task with a suitable solution to reduce the training cost. Third, we propose a utility estimator to avoid accessing the underlying data when calculating the utility of samples to reduce the calculation cost. By taking these three optimization mechanisms, RL-STuner can quickly tune the samples to adapt to the changing workload.